

What is Data Lineage Anyway?
Before dissecting my previous statement, let’s explore what data lineage is and who gains value from it. In my previous article, we highlighted the “many truths” that a data catalog needs to manage and maintain for various audiences. Data lineage follows a similar vein: technical resources want to see lineage that goes to the nth degree of detail, parsing code, extracting various transformations and enrichments across multiple technologies and persistent layers along the way. The result is usually a very detailed but cryptic visual blueprint of the data lifecycle for distinct business processes. Ask a business user to define their views on lineage, and it’s going to differ considerably from the technical perspective, with less granularity and technical jargon and much more conceptual and abstract language. Two different groups of users, each tasked with governing the data, have completely different expectations of what lineage should be.
Rendering lineages to both audiences is feasible. Many data governance providers can illustrate lineages from both the business and technical perspectives. The challenge is not in the visualization, but the ability to link both business and technical lineage sets in a fully automated manner is what’s lacking. Vendors typically provide separate views that have to be maintained. Synching the two usually involves considerable manual stitching efforts, drawing valuable resources to stitch between business and technical worlds. Over time this approach produces a “Franken-Data” map. This is not sustainable for the long term or effective across the vastness of a modern data ecosystem.

Introducing another challenge: metadata collection. In most cases this relies on the automated harvesting of various technical metadata, stitching it together into a cohesive end to end picture of data transparency. In the next section, we will focus on this effort and why the cost, effort and sheer vastness of technologies involved make the systematic collection and automatic stitching of lineage untenable.
Automated Technical Lineage
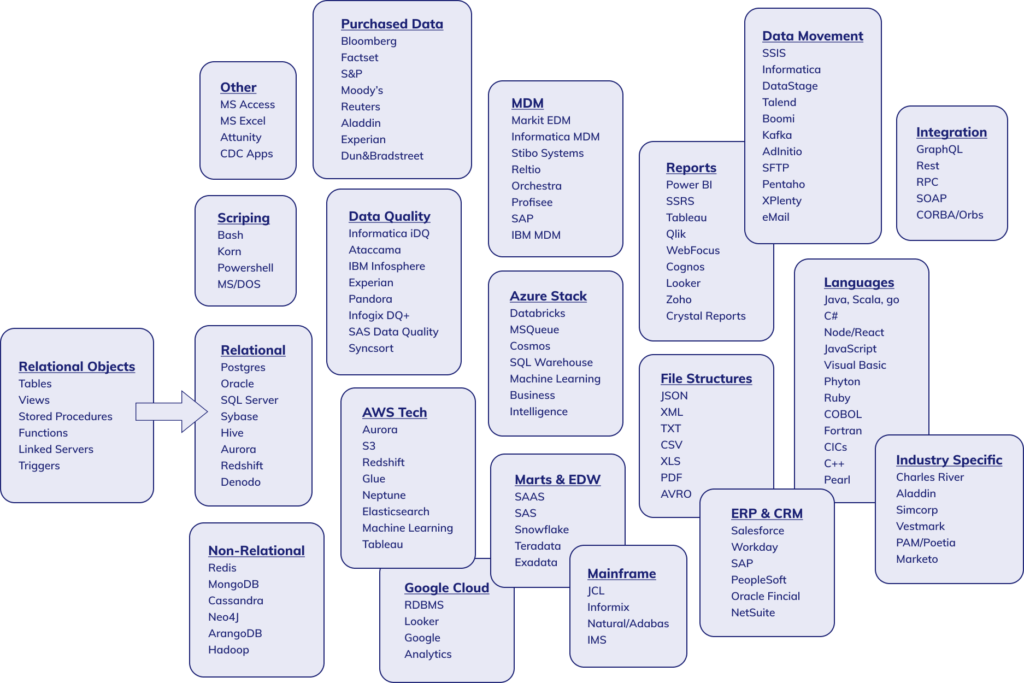
Modern day organizations have a vast and varied inventory of technologies in place ranging from legacy mainframe all the way through Big Data Analytic models. Illustrated above is a small cross sampling of some of the technologies that can be in use today. Although not a fully comprehensive listing, it still provides a perspective of the quantity of technologies and effort that a harvester has to understand in order to build some semblance of lineage. In addition to this, there are still a small minority of providers that are black-boxed and consider their metadata to be their intellectual property. For these providers, transparency is impossible beyond showing data entering and exiting the aforementioned black box object in a lineage diagram.
In open systems, metadata can be extracted, interpreted to some degree, and populated into a data lineage solution. Given this level of access, small providers initially started a cottage industry, providing metadata services for certain popular databases and ERP systems. As demand grew, this quickly evolved into a considerable marketplace for services and lineage construction across many established platforms.
Harvesting metadata, though initially seen as a simple task, is actually quite complex and expensive. As new technologies are introduced, there are inherent overheads to consider, from metadata extraction knowledge to some degree of expertise in those systems from which metadata is being extracted. Enterprise level tools can be expensive to acquire. Then add on the additional costs to ramp up training, install upgrades, and enable backward compatibility all while keeping a constant pulse on newer in-demand technologies. The cost of entry and sustainability is significant.
As a consequence, vendors have concentrated their efforts on connector verticals such as databases, ERP systems, mainframe, or popular big data platforms. In today’s marketplace, there’s not a single vendor that can provide comprehensive end to end automated solutioning across the breadth and depth of all technologies available today. For those who do have a solid portfolio of connectors, the metadata stores and format can change by a new version of the software, so what may be perceived as a single connector is actually set connectors by version. Customers typically get sticker shock for what they essentially view as a back end process and a simple means to an end for a broader data governance initiative.
For companies that have the budget and have acknowledged that multiple vendors are needed, can they get to a fully integrated end to end solution? In short …No. There are still a number of other considerations, risks, and unforeseen events that can impact one’s goal of a fully automated and unified data lineage solution.
There are things that we now know we don’t know. But there are also unknown unknowns
Donald Rumsfeld
Data driven organizations take pride in their technology investments and state of the art infrastructure, but pull back the cover and there’s nearly always some ugly stepchild hidden in the technology supply chain. A creaky but critical mainframe running COBOL, a manually populated MS Access Database, or the most popular database in the world – Microsoft Excel!! The extraction of metadata and lineage from these examples is close to impossible. Spreadsheets can be easily generated, duplicated, and moved with a simple “Save as” option outside the scope and realm of lineage extractors. In today’s world example (shown below), data can be extracted manually or programmatically incorporated into excel spreadsheets, enriched with outside data, and reported on without any IT oversight. Lineage alone, in this case, is not going to address General Data Protection Regulation (GDPR) or California Consumer Privacy Act (CCPA) reporting on ‘right to know’ or ‘right to be forgotten’ use cases.
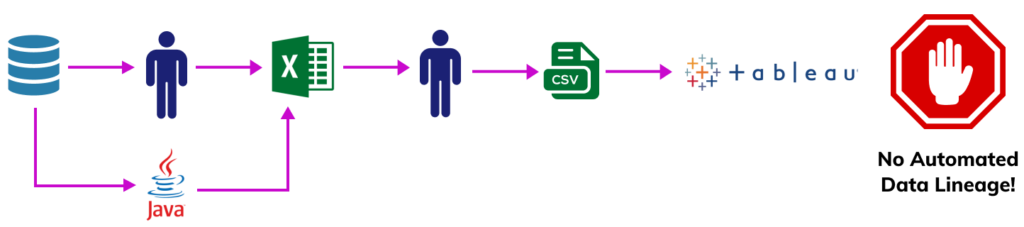
Programming languages have always been a popular way to extract, transform and push data across various systems. Unfortunately in today’s corporate environments there are many current and legacy languages and scripts in use, with newer languages constantly being introduced. To get a full view of lineage, one has to be able to parse the various languages and more importantly disambiguate the contents into some semblance of a source to target mapping. Parsing code has considerable challenges, COBOL can famously redefine layouts, assembly language pushes bytes around and solution providers have created their own proprietary languages like PeopleSoft’s PeopleCode and SAP’s ABAP to meet their specific needs. Modern languages can have multiple means of moving data from JDBC, REST, GraphQL, FileFactories to Message Queues and sockets. They also tend to be liberal with their implementation of standards, allowing developers a fair degree of “poetic license” in developing their code. We have yet to see a single provider successfully disambiguate a significant inventory of various programming languages and produce a comprehensive set of lineage flows when one considers the challenges expressed above.
As technologies evolve over time, procurement officers will take the initiative to engage with vendors for platform replacement. In the rare cases where there might be a question or two relating to metadata and data lineage, it’s safe to say most purchase decisions will not be undermined based on the vendor’s inability to automatically tie its metadata into the enterprise data lineage environment. Corporate acquisitions, in a similar vein, where someone else’s technologies are bestowed on you, typically don’t come with a data lineage blueprint, nor will the merger be canceled because of a lack of underlying metadata harvesting. Decisions are driven by business and take into account such things as revenue forecasts, cost reduction and EBITA, and rather than the need for up to date data lineage.
Life is really simple, but we insist on making it complicated
Confucius
Do we really need Data Lineage?
Over the years, data lineage has been promoted as the silver bullet to solve all regulatory, audit, and governance needs. In very specific use cases, with limited scope, it is, in fact, a viable and attainable solution. I have lost count of how many times I have heard “We absolutely 100% need data lineage and it’s a deal-breaker if it can’t be provided” or, almost as often, “Our regulation requires us to have data lineage”. When we peel back the layers, there are many assumptions made about what data lineage is and what it can and can’t deliver. BCBS 239 is often brandied about by vendors to promote data lineage as an absolute imperative for compliance, yet a 2017 McKinsey Report, “Living with BCBS 239”, highlighted the following:
“Most G-SIBs have focused on documentation and selective remediation. About one-third are documenting data lineage up to the level of provisioning data elements and including data transformation—though several are questioning the value of data lineage in the context of broader data controls.”
In most cases, data lineage is one option but rarely have I seen it called out as the only acceptable solution to meet a regulation. If the effort and cost of sustaining data lineage is being called out by the Global Systemically Important Banks (G-SIBS), one needs a sanity check before engaging in a full scale data lineage engagement. Here are some of the items to consider:
- It’s going to be a lot more expensive than you think.
- Multiple extraction vendors will be involved.
- There is no standard interchange between various vendor’s lineage mappings.
- There will be some level of manual stitching of data.
- There will be errors and omissions.
- Auditing, verification, and certification for lineage is going to be very hard.
- Business and Technical lineage is going to be hard to keep in synch.
- New technologies, upgrades, and acquisitions can break lineage.
- Cloud providers provide services and may not open up metadata for extraction.
- If it’s absolutely needed, provide lineage for pointed solutions, not enterprise wide.
The Alternative Approach – Don’t just trust the family tree, take the DNA test

Having looked at the lineage conundrum for quite some time, we came to the realization that a different approach was needed. If we take the analogy of ancestry one can research the family tree and get to a certain level of family history, but there will be gaps, language barriers, human errors, and omissions. An alternative method would be the use of DNA forensics to build a more accurate picture of your origin and possible health risks. With regard to an organization’s data, the Praxi approach de-emphasizes the means of movement and puts the focus wholly on data discovery, classification, and cataloging. Organizations can quickly identify what types of data they have and where it is located regardless of platform or location. As new systems are added or made redundant, the platform can instantly catalog and tag data DNA to provide context using established means of data patterns, curation, and machine learning models, allowing for the better identification of critical data to meet GDPR, CCPA or data provider restrictions. In essence, provide an inventory of the enterprise data with tagged sensitive or copyrighted content needed to meet various regulations are set in place.
To conclude, lineage is valuable but only in a cost controlled and scope restricted environment, with a set of outcomes that are pre-planned, demonstrable, and, most importantly, maintainable. In a modern world, where business users are more tech savvy than ever, they will not be shoehorned into solutions purely on the basis that they bode well for Data Lineage but fail to meet their ever changing business needs. IT needs to acknowledge the landscape change and the capabilities and limitations of Data Lineage, and leverage other approaches to complement and, in some cases, even supplant lineage altogether.
