

Find your needles, phone, tomatoes, and your keys too!

Remember that lost invitation to a wedding or losing your passport the morning you head out for a trip to Europe? Then you’re familiar with the significance of quickly locating a record when you need it and eliminating the clutter that gets in the way of quickly finding it. The rise of data clutter is a well-known problem. The scale and complexity of the information being collected today is beyond what was imagined even a few years ago and growing exponentially. Finding the needle you are after in this rapidly expanding haystack is more difficult than ever.
How Catalogs Help Answer “Where’s the data I need?”
Metadata management and data catalogs are methods of trying to wrestle with this issue. They attempt to answer the questions: where’s the data I need, how does it relate to other information in my organization, can I rely on it, and is it up-to-date?
Metadata management and catalogs have evolved through a number of generations over the last 15 years or so. A key concept was identified fairly early: placing business terms at the center of a web of connections, linked to data policies, rules, physical data, data quality results, integration scripts, codes, and many other attributes. Most crucially, business terms were connected to other business terms (IBM Infosphere Business Glossary 2008/9).
This approach has become an important paradigm in metadata management systems. Establishing conceptual models of business terms helps define other conceptual and logical models (differently structured models of the business area, for example). This web is thus strung together by physical “things”.
How to Create a Complete View of an Organization’s Data
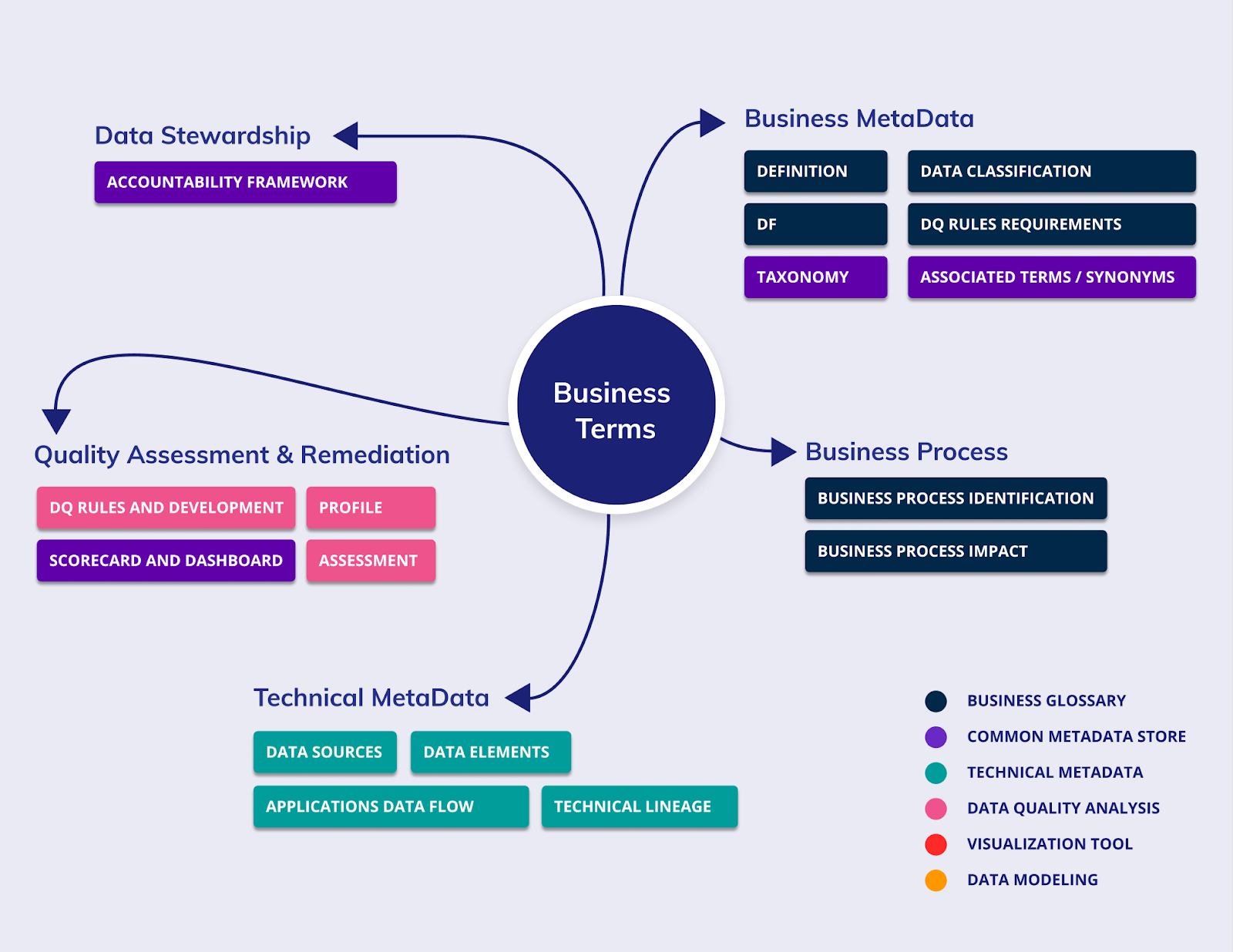
Connecting everything to a single conceptual model (often referred to as a canonical model), in principle, means that you can follow connections from one physical object to another. Eventually a full enterprise model develops. This is why the best data catalog and metadata repository applications are often based on Graph Theory (we’ll delve into that in a future post).
You Say Tomato, I Say Lycopersicon

Conceptual models operate similarly to the language Esperanto, i.e. as a single language through which all other languages are connected. Languages can be translated to others more efficiently than through traditional language-to-language translations. In theory, if everyone learns Esperanto, then we can all communicate in a common tongue. The same phenomenon applies to a canonical model approach to metadata management, allowing you to see all instances of “Customer”, for example, plus all its attributes in each instance.
Great Concept, “How do we get all that information?”
When catalogs first appeared, the intention was that data would be captured and managed manually. As the gigantic effort presented itself, metadata capture tools evolved to address it.
Products were developed in the mid-to-late 2000s using early versions of machine-learning algorithms (GlobalIDs 2001, Exeros 2002). These tools differed from earlier reverse-engineering solutions that analyzed data structures and sometimes reverse engineered code.
These new tools would search through the data itself and find information and assign similarities between like data. Once a correlation was established, it was up to a user to identify which component of the conceptual model that piece of data was related to in order to create the Esperanto-like view.
Information can be stored and made searchable in the products we now call data catalogs once a critical mass of data is gathered and organized (applying the conceptual model).
The Intrinsic Problem with Catalogs Emerges …
This presented a new problem. Connecting points to the conceptual model is a massive effort in its own right. Who is responsible for that effort and keeping catalogs up to date? That burden often falls on the data management team or data stewards.
This problem is at the heart of why catalog efforts are so challenging. Businesses prioritize focusing on the outcome of a usable and complete data catalog. Data teams often focus on the challenge and complexity in capturing and organizing the information needed to service a catalog. The gap between the two views is often where a catalog fails.
Here we’ve covered a bit of background and presented the core issue with catalogs. Next we’ll dig deeper into the ways catalog initiatives fail and what you can do to build a better foundation for your data program so that you can find those needles after all.
David Williams is an established technology executive with longstanding achievement in the financial industry, global data strategy, management, and governance. Areas of expertise include Enterprise Data Management Maturity (DMM), Software Development Methodology, Software Development Estimation, Data Governance and Stewardship, Data Management, Data Architecture, Data Standards, and Data Integration Strategy.
